Preface
有不少朋友都为写正则而头疼,不过笔者早已不为正则而烦恼了。本文分享一些我处理正则表达式的一些经验。全文分为正则利器,正则基础内容,正则进阶内容三个大块。
正则利器
首先推荐两个正则工具利器——分别是regex101(一个正则在线检验工具), Regulex(一个正则可视化工具)。这两个工具,可以大幅减小写正则的难度。做一个简单的演示, 比如常见的密码校验: 密码需要6位至18位,且只能为数字,字母,以及特殊字符,.*
先使用Regulex来在线编写正则。借助其将正则图形化的功能,我们很容易来修改调整自己的正则。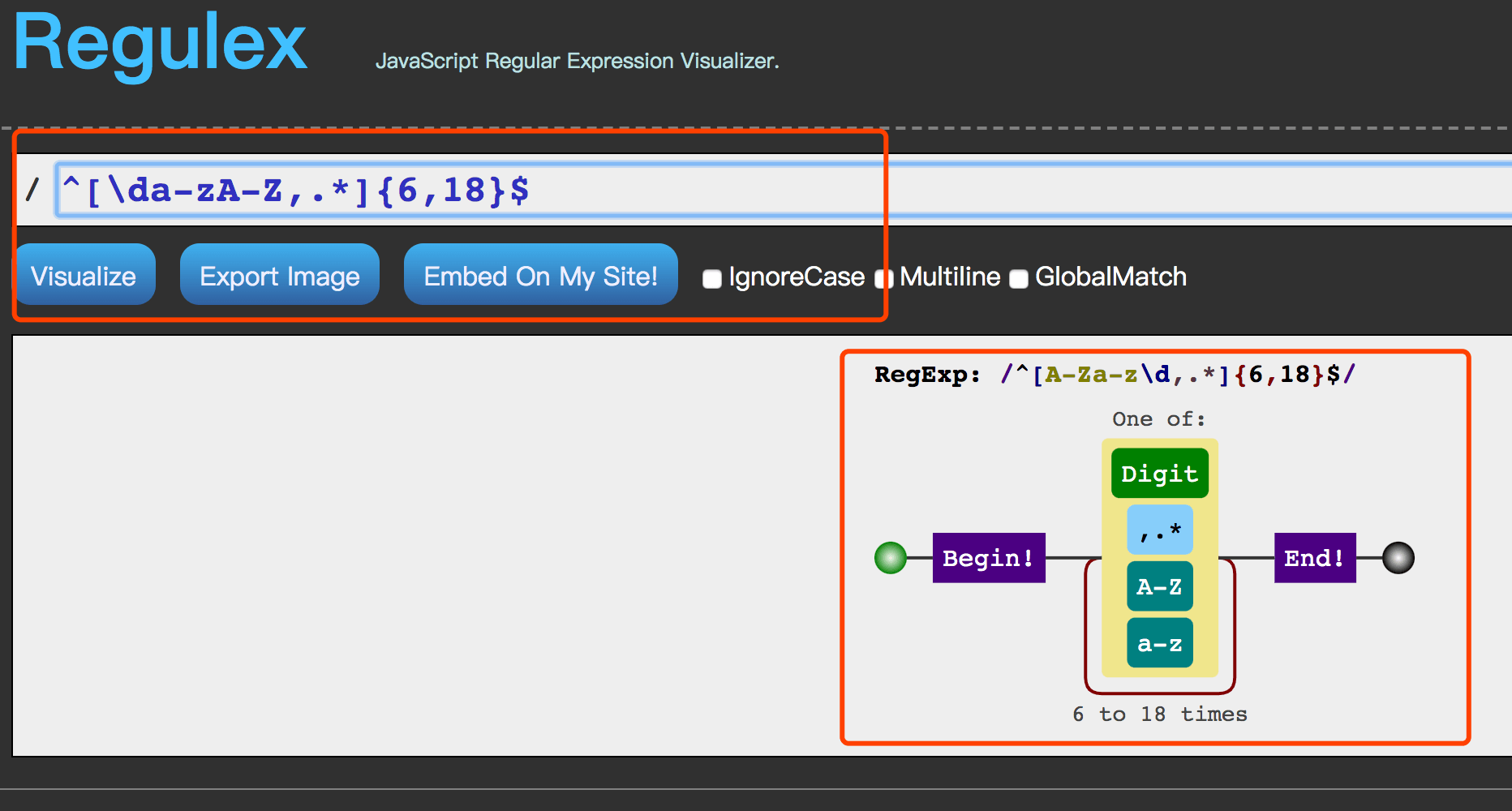
当通过Regulex工具写完正则过后,可以使用regex101来检查自己写的正则是否正确,以及匹配结果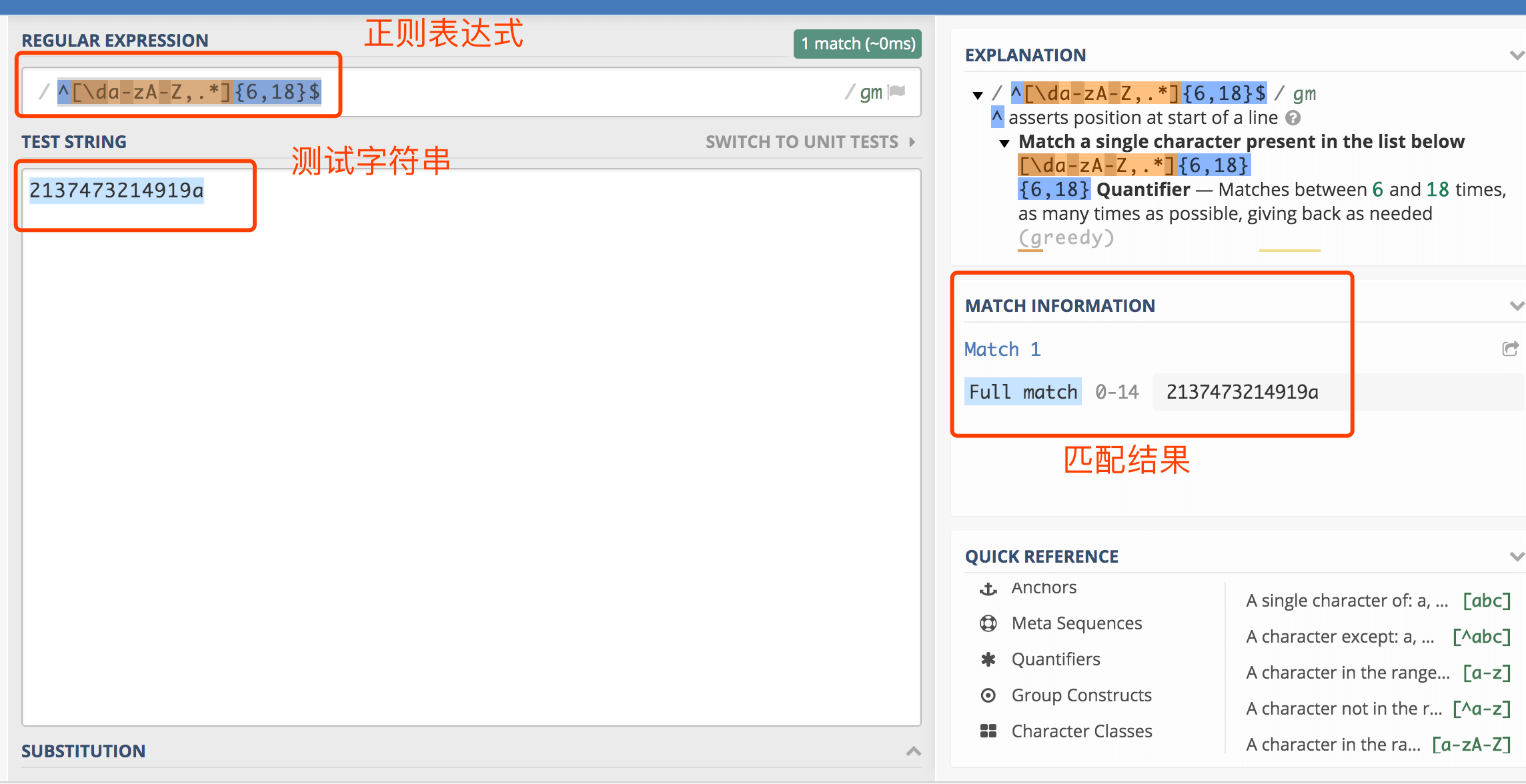
当上面两个流程走通过后,意味着该正则是符合我们需求且正确无误的,就可以迁移入代码中啦。
手撕正则
关于正则的相关知识,我强烈推荐这篇文章正则表达式30分钟入门教程。接下来我会将正则内容与JavaScript穿插起来讲。
JS创建正则表达式
在JS里有两种创建正则表达式的方式,分别是字面量和调用RegExp对象的构造函数。
使用一个正则表达式字面量,其由包含在斜杠之间的模式组成,如下所示:1
var re = /ab+c/;
脚本加载后,正则表达式字面量就会被编译。当正则表达式保持不变时,使用此方法可获得更好的性能。
或者调用RegExp对象的构造函数,如下所示:1
var re = new RegExp("ab+c");
在脚本运行过程中,用构造函数创建的正则表达式会被编译。 如果正则表达式将会改变,或者它将会从用户输入等来源中动态地产生,就需要使用构造函数来创建正则表达式。
总结一下,两种模式语法如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/pattern/flags
new RegExp(pattern [, flags])
RegExp(pattern [, flags])
参数如下:
pattern
正则表达式的文本。
flags
如果指定,标志可以具有以下值的任意组合:
g
全局匹配;找到所有匹配,而不是在第一个匹配后停止
i
忽略大小写
m
多行; 将开始和结束字符(^和$)视为在多行上工作(也就是,分别匹配每一行的开始和结束(由 \n 或 \r 分割),而不只是只匹配整个输入字符串的最开始和最末尾处。
u
Unicode; 将模式视为Unicode序列点的序列
y
粘性匹配; 仅匹配目标字符串中此正则表达式的lastIndex属性指示的索引(并且不尝试从任何后续的索引匹配)。
s
dotAll模式,匹配任何字符(包括终止符 '\n')。
上面参数提到的全局匹配,粘性匹配的知识在本文后面将做细致的讲解。
基础知识
这里先了解一些基础的正则知识,不做过多的讲解。
常用元字符
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
常用限定符
| 代码 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
常用的反义代码
| 代码 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
JS里的一些正则函数
在 JavaScript中,正则表达式也是对象。这些模式被用于 RegExp 的 exec 和 test 方法, 以及 String 的 match、matchAll、replace、search 和 split 方法。
test
test() 方法执行一个检索,用来查看正则表达式与指定的字符串是否匹配。返回 true 或 false。
1 | var str = 'hello world!'; |
exec
exec() 方法在一个指定字符串中执行一个搜索匹配。返回一个结果数组或 null。
在设置了 global 或 sticky 标志位的情况下(如 /foo/g or /foo/y),JavaScript RegExp 对象是有状态的。他们会将上次成功匹配后的位置记录在 lastIndex 属性中 。使用此特性,exec() 可用来对单个字符串中的多次匹配结果进行逐条的遍历(包括捕获到的匹配),而相比之下, String.prototype.match() 只会返回匹配到的结果。
1 | const regex1 = RegExp('foo*', 'g'); |
上面提到了正则表达式的global和sticky 两种模式,这里我详细讲下这两种模式。
全局模式
global这里是指全局匹配——找到所有匹配,而不是在第一个匹配后停止。用前面提到的密码正则^[\da-zA-Z,.*]{6,18}$来举个例子:
1 | # 非全局模式 |
上面的两段代码可以看到在全局模式下,正则的匹配结果为,true和false依次交替。这是因为: 在全局匹配模式下可以对指定要查找的字符串执行多次匹配。每次匹配使用当前正则对象的lastIndex属性的值作为在目标字符串中开 始查找的起始位置。lastIndex属性的初始值为0,找到匹配的项后lastIndex的值被重置为匹配内容的下一个字符在字符串中的位置索引,用来标识下次执行匹配时开始查找的位置。如果找不到匹配的项lastIndex的值会被设置为0。当没有设置正则对象的全局匹配标志时lastIndex属性的值始终为0,每次执行匹配仅查找字符串中第一个匹配的项。 lastIndex, 是一个可读可写的属性。需要特别注意是的,如前所述,正则表达当指定了g(全局匹配)或者y(粘性匹配),均会有这个效果。
全局匹配的一个使用场景——循环遍历,获取所有匹配。1
2
3
4
5
6var result = null;
while ((result = globalre.exec(str)) != null)
{
console.log(result[0]);
console.log(globalre.lastIndex);
}
当然使用matchAll()方法也可以实现该效果,这里不再赘述。
粘性匹配
sticky 属性反映了搜索是否具有粘性( 仅从正则表达式的 lastIndex 属性表示的索引处搜索 )。sticky是正则表达式对象的只读属性。sticky 的值是 Boolean ,并在“y”标志使用时为真; 否则为假。1
2
3
4
5
6
7
8var str = '#foo#';
var regex = /foo/y;
regex.lastIndex = 1;
regex.test(str); // true (译注:此例仅当 lastIndex = 1 时匹配成功,这就是 sticky 的作用)
regex.lastIndex = 5;
regex.test(str); // false (lastIndex 被 sticky 标志考虑到,从而导致匹配失败)
regex.lastIndex; // 0 (匹配失败后重置)
进阶知识
接下来我会讲一下,正则里面比较进阶且我觉得比较重要的内容。如前所述,这部分内容,我强烈推荐阅读这篇文章正则表达式30分钟入门教程。为了不做重复工作,这里我会讲得比较简略。
分支
所谓分支,是指有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。0\d{2}-\d{8}|0\d{3}-\d{7}
分组
所谓分组,类似于编码中的表达式的功能。用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了。如下所示(\d{1,3}\.){3}\d{1,3}
贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。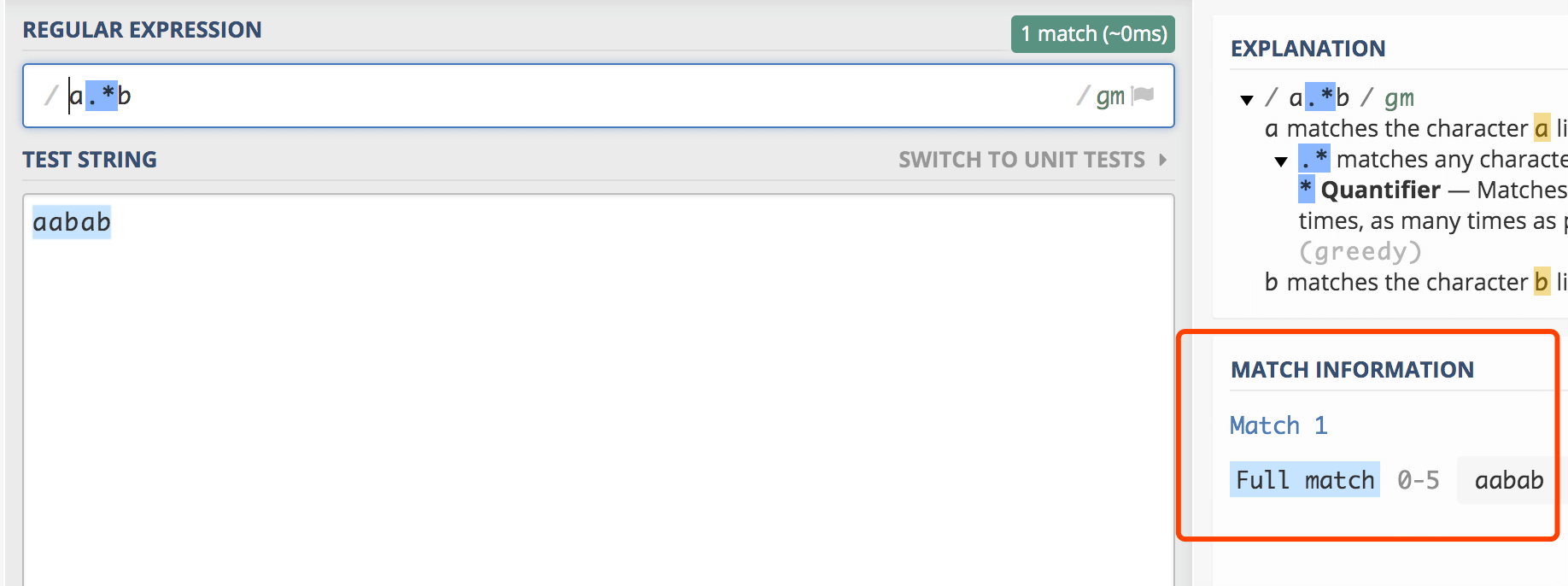
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?即可。懒惰限定符如下
| 代码 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,} | 重复n次或更多次 |
| {n,}? | 重复n次以上,但尽可能少重复 |
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。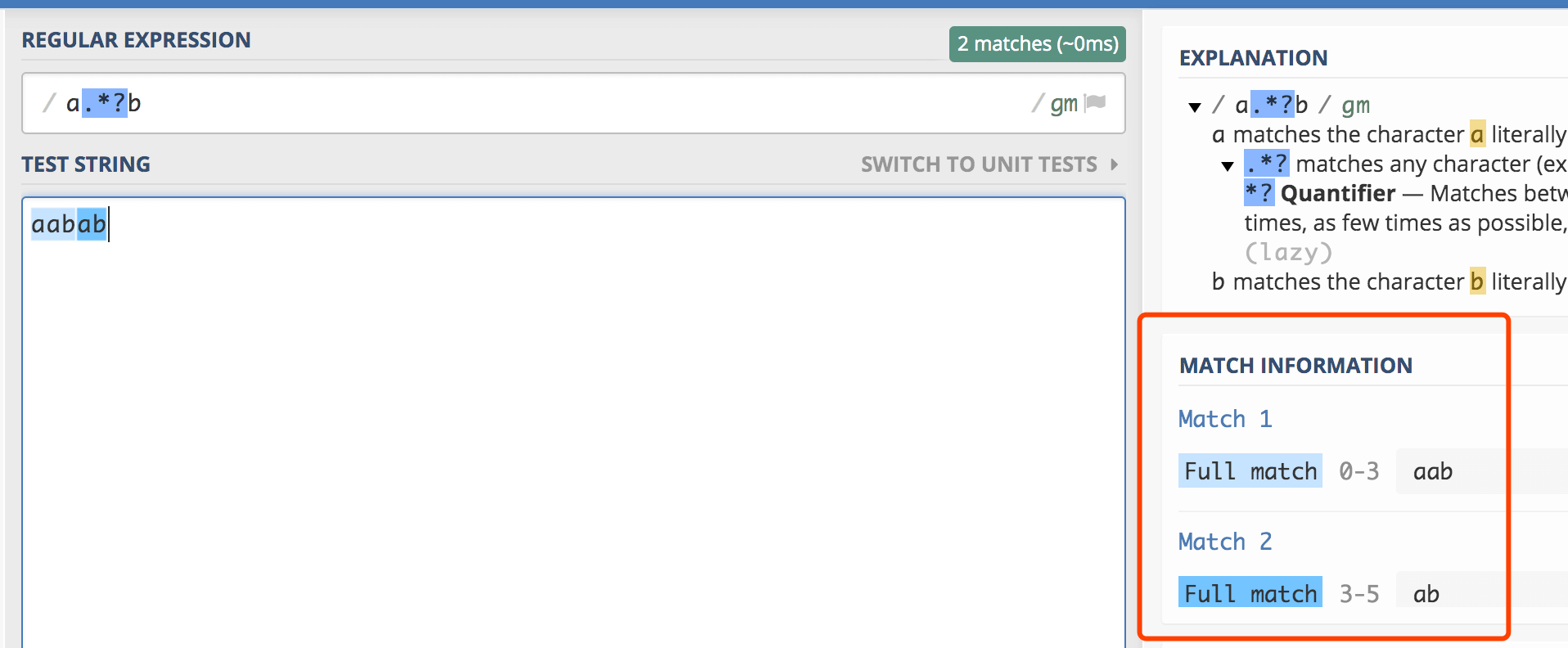
断言
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西, 也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
先行断言
x(?=exp),先行断言: exp紧跟x的情况下匹配x。例如,对于/Jack(?=Sprat)/,“Jack”在跟有“Sprat”的情况下才会得到匹配./Jack(?=Sprat)/ “Jack”后跟有“Sprat”或“Frost”的情况下才会得到匹配。不过, 匹配结果不包括“Sprat”或“Frost”。
1 | let regex = /First(?= test)/g; |
负向先行断言
x(?!exp),负向先行断言: x后无exp紧随的情况下匹配x。例如,对于/\d+(?!\。)/,数字后没有跟随小数点的情况下才会得到匹配。对于/\d+(?!\.)/.exec(3.141),匹配‘141’而不是‘3’。
1 | console.log(/\d+(?!\.)/g.exec('3.141')); // [ '141', index: 2, input: '3.141' ] |
后行断言
(?<=exp)x,后行断言: x紧随exp的情况下匹配x。例如,对于/(?<=Jack)Sprat/,“Sprat”紧随“Jack”时才会得到匹配。对于/(?<=Jack|Tom)Sprat,“Sprat”在紧随“Jack”或“Tom”的情况下才会得到匹配。不过,匹配结果中不包括“Jack”或“Tom”。
1 | let oranges = ['ripe orange A ', 'green orange B', 'ripe orange C',]; |
负向后行断言
(?<!exp)x,负向后行断言: x不紧随y的情况下匹配x。例如,对于/(?<!-)\d+/,数字紧随-符号的情况下才会得到匹配。对于/(?<!-)\d+/.exec(3) ,“3”得到匹配。 而/(?<!-)\d+/.exec(-3)的结果无匹配,这是由于数字之前有-符号。
断言实战
提取字符串123sadf21(aaaaf213sdaf),括号中的部分。
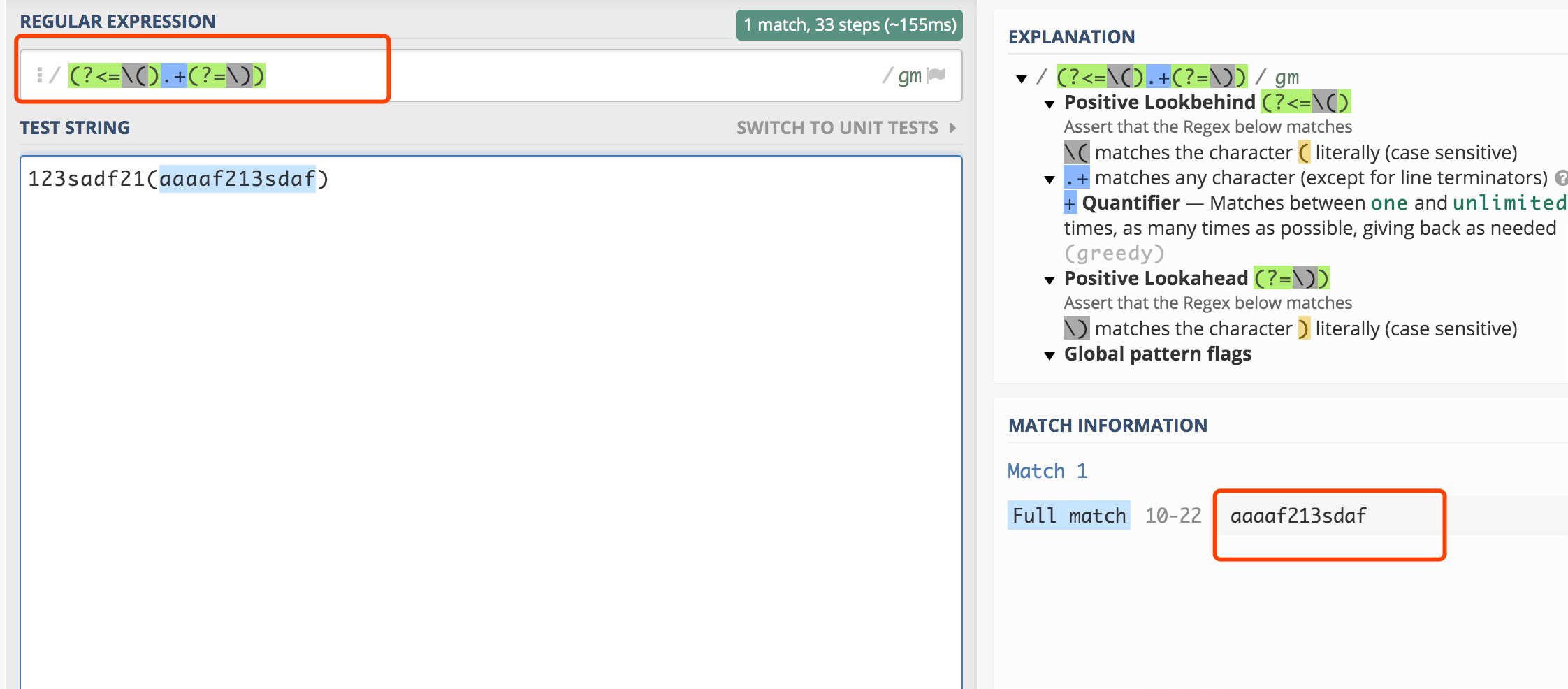
如上图所示,(?<=\().+(?=\)), 该正则分为三部分:(?<=\(,这是后行断言;(?=\)), 这是先行断言;.+,匹配任意长的字符。
写在最后
以上就是本文的所有内容。正则使用得好,能起到事半功倍的作用。利用好本文推荐的工具,多加练习,相信正则一定不再是烦恼!